The Good: мы протестировали 6 AI-инструментов для исследований против реальных пользователей — вот что нашли

Команда UX-исследователей The Good провела практическую оценку шести AI-инструментов для пользовательских исследований в течение февраля и марта. Инструменты тестировались на реальных клиентских проектах, а результаты сравнивались с данными, полученными проверенными исследовательскими методами. Вывод команды: «Некоторые из этих инструментов действительно полезны для правильной команды в правильной ситуации.»
Классификация: семь типов AI-возможностей для исследований
Прежде чем оценивать конкретные инструменты, команда выделила семь различных типов AI-возможностей в исследовательских инструментах:
- AI-ассистированная настройка исследования — проектирование исследований или написание тест-планов.
- AI-модерация интервью — AI ведёт разговор, заменяя живого модератора.
- Синтетические пользователи — AI-персоны, симулирующие ответы пользователей.
- AI-уточняющие вопросы — динамическое зондирование на основе ответов участников.
- AI-анализ и синтез — тематическое кодирование ответов, генерация саммари.
- AI-инструменты для roadmap — сканирование сайтов с выдачей приоритизированных UX-рекомендаций.
- AI-тепловые карты — предсказание визуального внимания без реальных данных пользователей.
Synthetic Users
Категория: синтетические пользователи / AI-ассистированная настройка исследования.
Функция: генерирует AI-профили пользователей и симулирует их ответы на скриншоты или Figma-прототипы, создавая отчёты по юзабилити с находками, цитатами и приоритизированными рекомендациями.
Методология тестирования
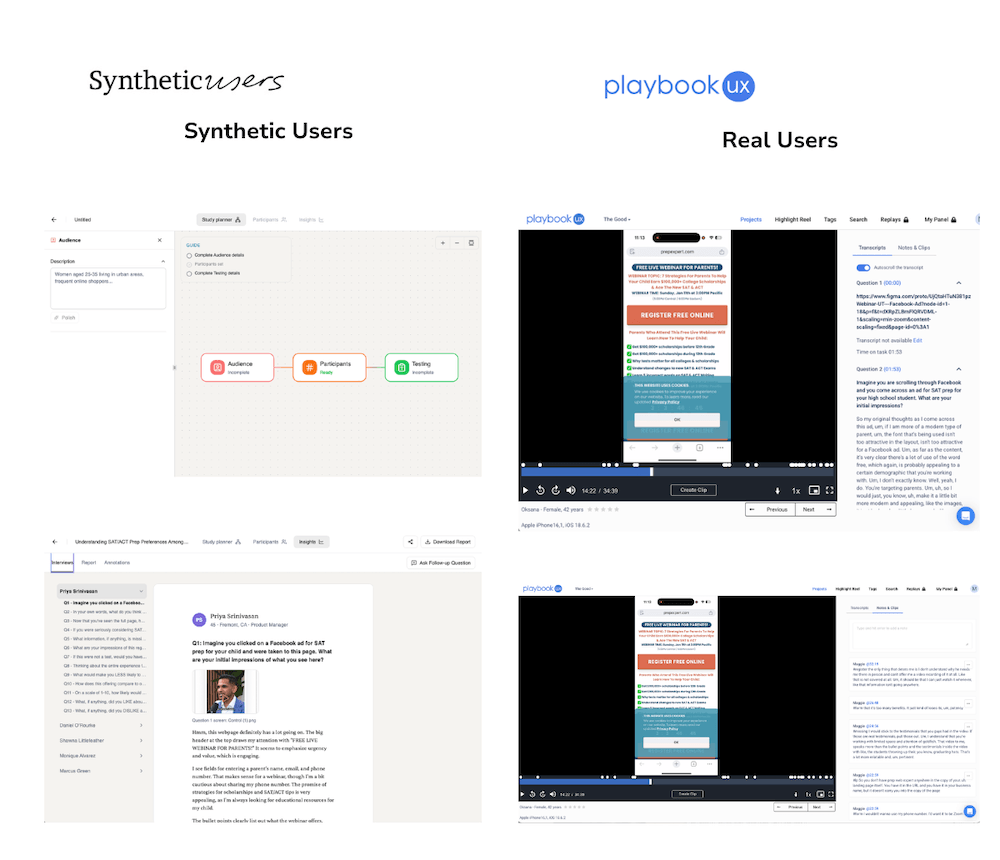
Стратег агентства провёл идентичные тесты через Synthetic Users и через PlaybookUX с реальными рекрутированными участниками — на одной и той же посадочной странице, с одними и теми же исследовательскими вопросами.
Где результаты совпали
Оба подхода выявили перегруженность информацией и захламлённый дизайн. Оба зафиксировали опасения по поводу конфиденциальности при вводе номера телефона. Оба отметили скептицизм в отношении маркетинговых обещаний. Ранжирование по серьёзности проблем оказалось сопоставимым. Синтетические «цитаты пользователей» напоминали формулировки реальных участников.
Ключевые различия
Synthetic Users не умеет тестировать живые URL — только скриншоты и Figma-прототипы. Реальные пользователи давали поведенческие данные (паттерны кликов, моменты колебаний, поведение при скролле), которые синтетические пользователи воспроизвести не в состоянии.
Сгенерированный отчёт содержал восемь разделов со значительными повторами. Одни и те же три-четыре находки появлялись в executive summary, потасковом анализе, паттернах ошибок, пользовательских потоках, оценке learnability, рейтингах удовлетворённости и рекомендациях.
Оценка
Команда охарактеризовала инструмент как «быстрый автоматизированный эвристический аудит». Он выявляет очевидные проблемы, но не способен зафиксировать, как реальные пользователи взаимодействуют с опытом. Лучше всего использовать как стартовую точку, а не как полноценную замену поведенческого тестирования.
Uxia
Категория: синтетические пользователи / тестирование прототипов.
Функция: создаёт кастомных AI-пользователей на основе предоставленного описания аудитории и тест-плана. Пользователи проходят через прототипы; инструмент автоматически создаёт ранжированные темы, находки и отчёты, готовые к отправке.
Методология тестирования
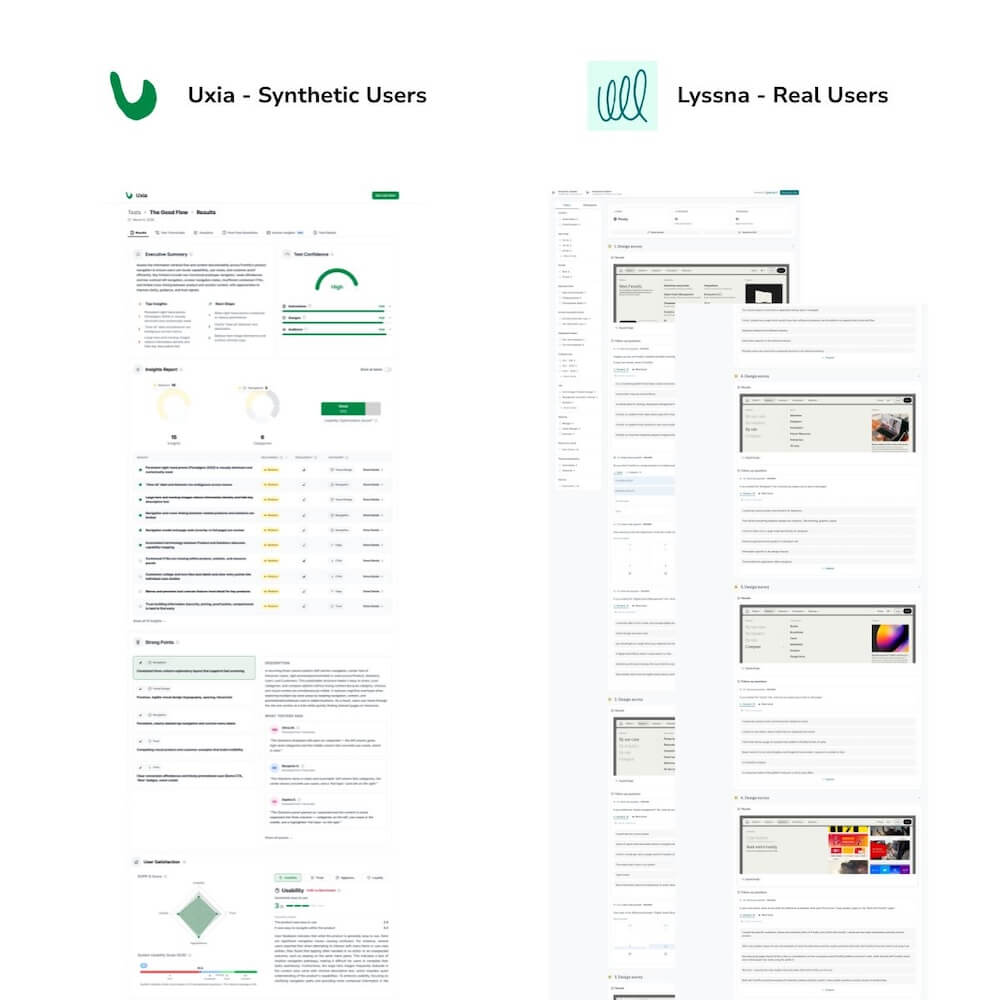
Исследователь предоставил Figma-прототип, который уже был протестирован с реальными участниками через Lyssna, что позволило напрямую сравнить результаты AI с реальными данными.
Выявленные сильные стороны
Автоматический вывод с предварительно ранжированными темами. Готовые к отправке отчёты, не требующие ручного анализа. Реальная экономия времени для in-house команд без выделенных исследователей. Инструмент обнаружил ту же главную находку, что и тестирование с реальными пользователями. Честное позиционирование: Uxia открыто представляет себя как дополнение, а не замену.
Ограничения
AI-пользователи интерпретировали placeholder-изображения как реальный контент. Путали меню навигации с самостоятельными страницами. Не проявляли эмоционального интеллекта, который привносят реальные пользователи. Синтетические ответы лишены независимости: тридцать AI-ответов равны одному мнению, умноженному на тридцать.
Ограничения по типам тестов
Инструмент не может проводить многие типы тестов, доступные с живыми участниками. Он ловит поверхностные точки трения (нерабочие потоки, запутанную вёрстку, нарушенную иерархию), но пропускает нюансированные реакции, которые определяют решения по оптимизации.
Цена: индивидуально для каждой команды.
Оценка
Лучше всего использовать как этап перед тестированием с живыми пользователями. Полезен для выявления тупиковых веток в прототипах на ранних этапах или для формирования концепций A/B-тестов. Не замена поведенческого исследования.
Maze
Категория: AI-модерация интервью / немодерированное тестирование.
Функция: платформа для немодерированного юзабилити-тестирования с добавленными AI-функциями, включая AI-модерацию интервью.
Процесс оценки
Команда провела полный обзор платформы и протестировала основные возможности.
Находки
Maze существует до появления AI и представляет собой стандартный инструмент для немодерированного тестирования, добавляющий AI-возможности поверх основного продукта, а не платформу, изначально построенную вокруг AI. Функция AI-модерации нацелена на команды, проводящие большие объёмы модерированных исследований и стремящиеся масштабировать их без расширения штата.
Функция AI-уточняющих вопросов на практике оказалась ограниченной. Она извлекает слова из ответов участника и запрашивает подробности — по сути, это «продвинутый piping в опросах». Это лучше статических анкет, но не заменяет квалифицированного модератора, ведущего настоящий исследовательский диалог.
Оценка
Добротный инструмент для немодерированного тестирования, где AI-модерация наиболее полезна агентствам или in-house командам, проводящим десятки модерированных сессий ежемесячно. Для команд, довольных существующими инструментами вроде Lyssna, убедительных причин переключаться нет.
Strella
Категория: AI-модерация интервью / анализ и синтез.
Функция: заменяет человека-модератора AI, который ведёт голосовые интервью, затем автоматически генерирует нарезки ключевых моментов, сегментационный анализ и синтезированные отчёты с находками.
Подход к оценке
Исследователь прошёл детальную демонстрацию и обзор возможностей.
Заслуживающие внимания возможности
Автоматические highlight-ролики, AI-сегментация и аналитические интерфейсы с возможностью задавать вопросы по данным могут экономить время организациям, проводящим большие объёмы качественных исследований.
Критическое ограничение
Цена от 5 000 долларов за проект (без учёта рекрутинга участников и вознаграждений) делает экономику работоспособной только для организаций, часто проводящих масштабные интервьюные исследования.
Команда признала, что не смогла напрямую сравнить модерированные интервью с реальными модераторами и AI-модерированные, поскольку нечасто проводит живые модерированные сессии для клиентов. Их рекомендация — провести прямое тестирование прежде, чем делать окончательные выводы о качестве.
Оценка
Потенциально ценен для агентств или enterprise-команд, проводящих 20 и более модерированных исследований в год. Текущая ценовая модель затрудняет использование для большинства in-house команд по оптимизации.
Baymard UX-Ray
Категория: AI-инструмент для roadmap и рекомендаций.
Функция: сканирует сайты и генерирует приоритизированные UX-рекомендации, опираясь на исследовательскую библиотеку Baymard для категоризации и ранжирования проблем по типу страницы и серьёзности.
Процесс тестирования
Результаты оценивались на реальных сайтах, методология изучалась, команда посетила вебинар Baymard, на котором основатели обсуждали точность AI в UX-рекомендациях.
Находки
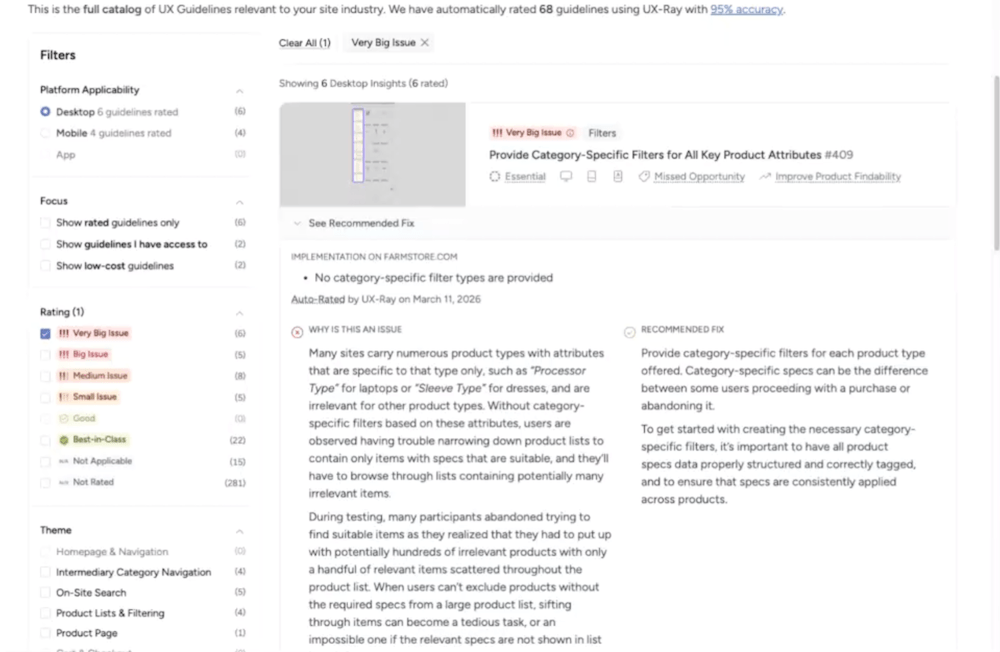
UX-Ray сгенерировал 342 UX-инсайта для одного сайта. Команда отметила, что объём отличается от полезности. Многие инсайты требуют платного тарифа для просмотра. Без приоритизации по бизнес-влиянию, потенциальному доходу или сложности внедрения 342 находки скорее перегружают, чем информируют.
Интерфейс при этом качественный — динамичный, кликабельный, организован по типам страниц с превью. Проверенная контентная библиотека Baymard добавляет авторитетности.
Фундаментальное ограничение
Инструмент лишён контекста. Он сканирует на соответствие библиотеке лучших практик, но не имеет доступа к реальному поведению пользователей, специфике аудитории или данным о том, где именно возникает конверсионное трение. Технически корректные рекомендации могут оказаться нерелевантными или контрпродуктивными для конкретных сегментов посетителей и паттернов трафика.
Команда подчеркнула: «Лучшие практики — это стартовая точка, а не стратегия.»
Примечание о точности: на вебинаре основатели Baymard заявили, что точность AI-генерируемых UX-рекомендаций в индустрии составляет около 70%. Baymard заявляет о примерно 95%-й точности, однако рекомендации всё равно требуют тестирования перед внедрением.
Цена: 399 долларов в месяц за средний тариф.
Оценка
Полезен для команд, которым нужна структурированная стартовая точка для аудита и которые обладают экспертизой для оценки и фильтрации результатов. Не замена для исследовательски обоснованной стратегии оптимизации.
Brainsight
Категория: AI-тепловые карты.
Функция: генерирует предиктивные карты внимания без реальных данных пользователей, используя AI, обученный на данных eye-tracking исследований, для моделирования того, куда пользователи будут смотреть.
Подход к тестированию
В отличие от других инструментов, The Good уже использует Brainsight в работе с рядом клиентов, поэтому оценка основана на практическом опыте, а не на свежем тестировании.
Основные сильные стороны
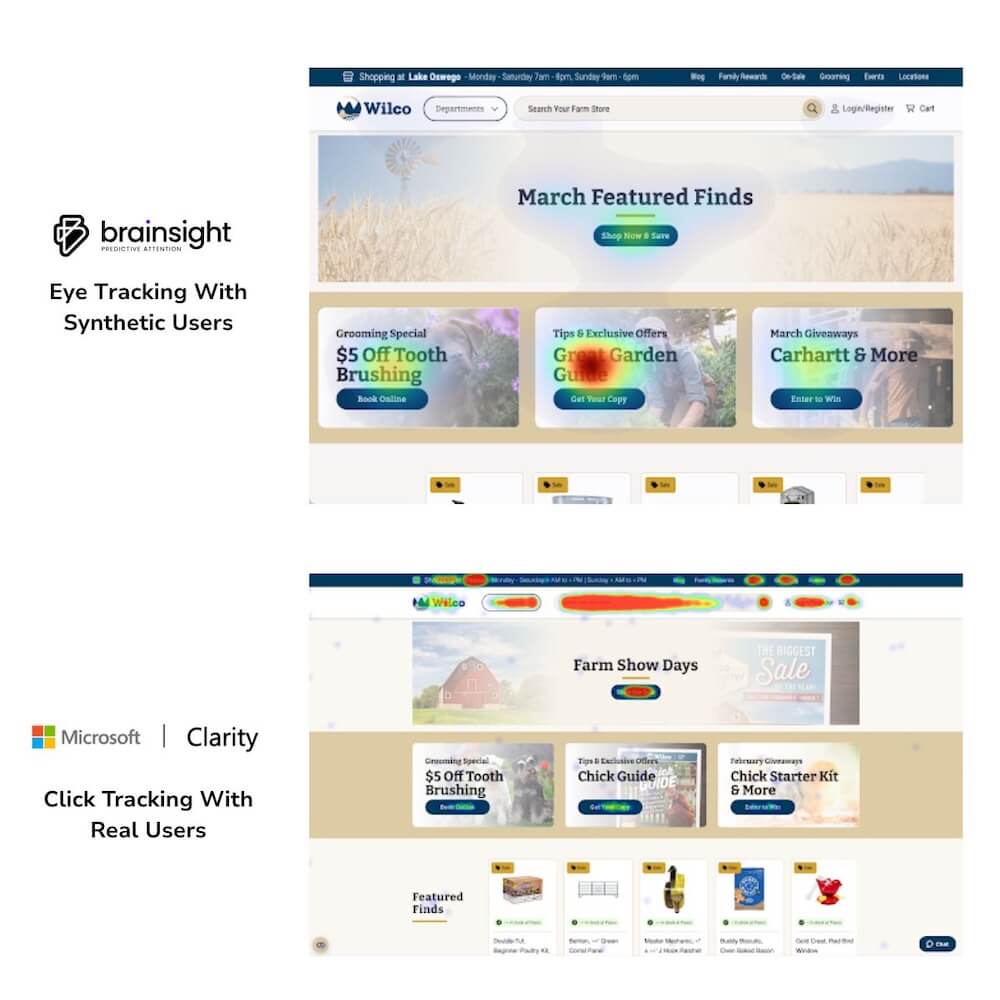
Надёжен как стартовая точка. Корректно считывает контраст, текст, изображения и тёмные области для оценки зон концентрации внимания. Работает заметно надёжнее, чем DIY-альтернативы на основе AI (которые команда нашла стабильно ненадёжными). Доступная цена, которая реально работает как входная точка для команд, не имеющих инвестиций в eye-tracking исследования.
Важная оговорка
Инструмент моделирует визуальную заметность (visual salience), а не реальное поведение пользователей. Настоящие тепловые карты показывают, куда пользователи действительно смотрели и с каким намерением; предиктивные тепловые карты показывают, куда AI предполагает посадку внимания на основе визуальных характеристик. Реальные пользователи могут игнорировать высококонтрастные области, не читая их, — AI этот поведенческий выбор предсказать не может.
Характеристика команды
«Доводит до 70% ответа быстрее и дешевле, чем бездействие.» Пользователи видят концентрацию внимания, точки ухода и визуальную конкуренцию элементов. Оставшиеся 30% — понимание того, почему пользователи смотрят куда смотрят, что они делают дальше и какие из этого следуют стратегические выводы для конверсии — требуют полноценной оптимизационной стратегии.
Будущее развитие
Brainsight добавляет AI-генерируемые рекомендации поверх тепловых карт — функцию, которую команда пока не оценила полностью, но отметила для пристального наблюдения.
Оценка
Рекомендуется как доступная входная точка в данные о внимании. Следует позиционировать как стартовый анализ с честным признанием того, что реальные данные о вовлечённости дают более полное понимание.
Сквозные темы по результатам тестирования
Тема 1: объём ≠ полезность
Многие инструменты генерируют избыточное количество находок. 342 инсайта UX-Ray и восемь разделов отчёта Synthetic Users с повторами демонстрируют, что количество скорее затуманивает, чем проясняет направление для действий.
Тема 2: контекст критически важен
AI-инструменты, анализирующие без понимания специфического поведения аудитории, бизнес-моделей или конверсионного трения, часто выдают технически корректные, но стратегически нерелевантные рекомендации.
Тема 3: поверхностная точность vs. поведенческий инсайт
Несколько инструментов точно определили очевидные проблемы юзабилити, но пропустили эмоциональные реакции, неожиданные обходные пути и нюансированные поведенческие сигналы, которые определяют реальные решения по оптимизации.
Тема 4: честное позиционирование коррелирует с ценностью
Инструменты, которые открыто позиционируют себя как дополнение (а не замену) реальных исследований — как Uxia — формируют более реалистичные ожидания пользователей и лучше встраиваются в исследовательские рабочие процессы.
Тема 5: данные от реальных пользователей незаменимы
Независимые поведенческие сигналы от нескольких реальных участников невозможно синтезировать. Находка, повторяющаяся у двадцати реальных пользователей, представляет надёжный сигнал; идентичный вывод от AI — одно мнение, умноженное на двадцать.
Когда AI-инструменты для исследований имеют смысл
Лучшие сценарии использования:
- Альтернатива — не проводить исследование вообще.
- Нужен быстрый ориентир по чётко определённым вопросам с невысокими ставками.
- Предзапускной QA прототипов перед инвестицией в тестирование с живыми участниками.
- Существующие данные требуют ускоренного синтеза.
Неподходящие сценарии:
- Решения по оптимизации с высокими ставками.
- Выход на незнакомый рынок, где нужно учиться.
- Ситуации, требующие обоснованных поведенческих доказательств.
Общий вывод
Команда определила, что AI-инструменты для исследований заполняют конкретные пробелы для определённых команд и ситуаций. Ни один не работает как полная замена исследований с реальными пользователями. Наиболее ценные инструменты были честны в отношении своих ограничений и интегрировались в существующие исследовательские процессы, а не пытались их вытеснить.
Приоритет рекомендаций по результатам тестирования:
- Brainsight — доступная входная точка в данные о внимании.
- Uxia — полезная предварительная валидация прототипов.
- Synthetic Users — быстрый эвристический аудит.
- Baymard UX-Ray — структурированная стартовая точка для аудита.
- Strella — нишевый enterprise-сценарий.
- Maze — инкрементальное улучшение существующих инструментов.