arXiv: как LLM помогают исследователям политики анализировать неструктурированный текст
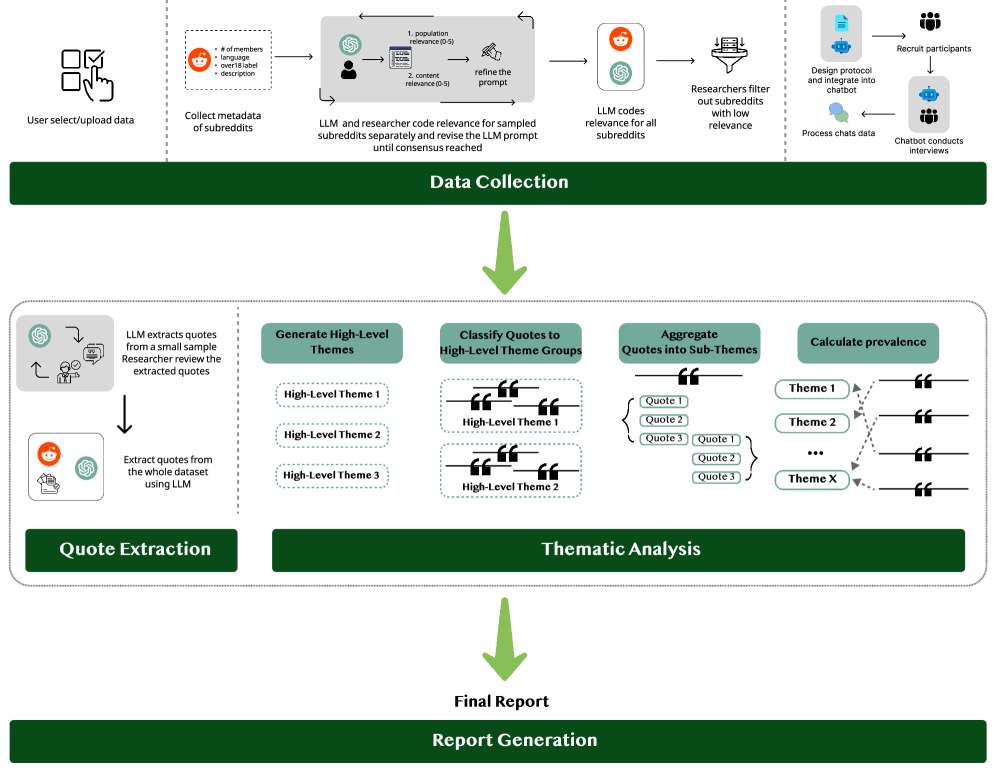
Исследовательская группа Принстонского университета совместно с Нюрнбергским институтом рыночных решений опубликовала препринт, в котором оценивает возможности рабочих процессов на основе LLM для тематического анализа неструктурированного текста в контексте policy research. Статья описывает два исследования: пользовательское тестирование прототипа интерфейса с участием 11 профессиональных policy researchers и крупномасштабный сравнительный анализ данных из Reddit и транскриптов интервью.
Контекст и постановка задачи
Policy research традиционно опирается на опросы, интервью, фокус-группы и слушания — методы, хорошо зарекомендовавшие себя для получения репрезентативных оценок общественного мнения. Однако все они дорогостоящие, медленные и ограничены кругом участников, у которых есть время и ресурсы для участия. В результате аналитические материалы нередко не включают перспективы недостаточно представленных сообществ.
Параллельно онлайн-форумы и социальные сети накопили огромные объёмы текстов, в которых люди обсуждают те же самые вопросы политики — зачастую откровеннее и с конкретными примерами из жизни. Reddit, в частности, организован в тематические сообщества, что делает его привлекательным источником для тематического анализа. Но работать с миллионами постов вручную невозможно.
Авторы статьи адаптировали и расширили фреймворк QuaLLM — конвейер многоэтапных промптов, который извлекает темы из неструктурированного текста — специально для нужд policy researchers. Ключевой исследовательский вопрос: может ли такой инструмент помочь исследователям быстро ориентироваться в больших массивах текстовых данных, и насколько его результаты соответствуют выводам авторитетных аналитических отчётов?
Исследование 1: пользовательское тестирование
В первом исследовании 11 опытных policy researchers работали с прототипом интерфейса, который позволял выбирать суббреддиты как источники данных, задавать высокоуровневые темы и просматривать структурированные отчёты с подтемами и цитатами. Участники исследовали две темы: использование социальных сетей несовершеннолетними и изменение климата.
Участники в целом воспринимали инструмент как полезный способ быстро получить «приблизительное» представление о том, что обсуждается в публичном пространстве. Однако часть исследователей выразила скептицизм по поводу Reddit как источника данных: аудитория платформы не репрезентативна для общей популяции, а обсуждения нередко концентрируются вокруг специфических интересов конкретных сообществ. Участники рассматривали инструмент как способ дополнить, а не заменить традиционные методы — особенно для ранних стадий исследования, когда нужно быстро понять, о чём вообще идёт разговор.
Исследование 2: масштабный сравнительный анализ
Второе исследование было посвящено экономическому влиянию ИИ и сравнивало результаты тематического анализа из двух источников. Первый — данные Reddit: авторы отфильтровали 25 691 суббреддит, отобрали релевантные посты и извлекли 122 191 цитату из 5 491 991 поста. Второй — 1058 транскриптов полуструктурированных интервью, проведённых чат-ботом с демографически разнообразной выборкой взрослых жителей США. Оба набора данных были обработаны одним и тем же рабочим процессом на основе LLM, а полученные темы сопоставлены с темами из авторитетных аналитических отчётов по ИИ и экономике.
Результаты показали, что рабочий процесс воспроизводил большинство тем, присутствовавших в авторитетных отчётах. При этом анализ Reddit и интервью позволил выявить дополнительные темы, специфичные для онлайн-сообществ и отсутствующие в официальных документах, — в первую очередь ранние, формирующиеся опасения и конкретные пользовательские истории. Вместе с тем авторы зафиксировали и ограничения: проблемы с метаданными, вопросы репрезентативности и недостаток доверия к сгенерированным ИИ резюме со стороны некоторых участников.
Выводы и применимость для UX и market research
Авторы позиционируют LLM-assisted рабочий процесс как инструмент дополнения, а не замещения традиционных методов исследования — прежде всего для первичного изучения темы, когда необходимо быстро охватить большой объём текста. Инструмент снижает затраты на ручное кодирование и позволяет работать с масштабами данных, недоступными для стандартного качественного анализа.
Для UX-исследователей и market researchers статья интересна прежде всего тем, что демонстрирует практически применимый подход к тематическому анализу больших массивов неструктурированного текста — форумов, транскриптов интервью, отзывов. Авторы явно обозначают, что цель не в замене участников-людей синтетическими данными, а в обработке реальных человеческих высказываний с помощью LLM. Фреймворк QuaLLM доступен как open-source инструмент и рассчитан на исследователей без навыков программирования.
Препринт опубликован 7 апреля 2026 года. Авторы: Юхань Лю, Шуяо Чжоу, Якоб Кайзер, Элла Колби, Дженнифер Окуара, Мэгги Ванг, Варун Нагарадж Рао и Андрес Монрой-Эрнандес.